

One core feature in the recently-released c-lightning v0.9.0 is the support for multi-part payments (MPP). MPP is a method to split a single payment into a number of smaller parts that can be sent over separate routes in the Lightning Network, and recombined at the recipient. This allows larger payments to be sent over the Lightning Network by combining the capacity of multiple channels, eliminating individual channel limitations as a bottleneck.
How Does MPP Work?
Each partial payment is contingent on the same payment_key (matching the payment_hash from the invoice) being published. This means that either all parts are transferred or none are—the overall payment remains atomic. It also means that the invoice and payment_key retain their proof-of-payment function. The recipient is in control of whether to claim the parts or not.
Receiving a payment therefore simply requires the recipient to collect all incoming partial payments and wait for the full amount before releasing the payment_key. This is pretty simple and has been part of c-lightning since version 0.8.1.
Advantages of MPP
On the other hand, the sender side of multi-part payments is rather complex and quite a number of technical choices go into implementing it. In this post, we will try to walk through the requirements, constraints, and the solutions we came up with. But before diving into the technical details, let’s revisit what MPP is good for:
- Enable larger payments: We can combine the capacity of multiple channels allowing us to send and receive payments that would exceed the capacity of any single channel.
- Allow better fund allocation: Since the size of the payments we can perform is no longer constrained by the highest capacity channel, we can spread the funds at our disposition to a number of channels and peers, reducing our reliance on individual peers being online when we need them.
- Increase payment privacy: The total payment amount is split into smaller parts so that intermediate nodes no longer see the total amount being transferred. Instead, they can only see the parts that they are involved in forwarding. This makes it harder for them to guess the overall amount, as well as breaking heuristics that try to guess the destination based on round amounts (something that previously required us to randomly overpay to simulate fees going to a shadow route).
- Better use of network resources: By spreading the load of payments over more routing nodes, the fees are distributed to more nodes. Nodes can also more easily keep their channels balanced by forwarding many smaller payments, rather than facing the occasional big payment for which capacity is insufficient.
What Are the Constraints?
The main goal of the MPP implementation is to maximize the chances of a payment succeeding, even in very constrained scenarios or with large payment amounts. We also have secondary goals such as minimizing the time to completion and keeping the fees paid within a reasonable range.
Any decision we make when implementing multi-part payments is a tradeoff. For example, we might be tempted to simply split a payment into the smallest feasible parts, and then send them all at once. This might seem like a good idea initially since it uses as much capacity of channels as possible, returning only the excess which then needs to be retried on other routes, resulting in very short completion times. However, it’d also result in very large fees, due to the fixed base fee that each node charges for each forwarded (partial-)payment. In addition, it’d pretty quickly bump against another constraint: the maximum number of HTLCs that can be added to a channel.
Overall we identified the following constraints and tradeoffs:
- Capacity limitations on the channels that we’d like to use as part of our routes. For some of the channels, we might know the exact capacity because we are one of the endpoints. But most of the time the channels are remote and we don’t have a clear picture of what the capacity distribution is, which prevents us from knowing whether a payment of a given size can be routed through. Since we cannot know the current capacity, trial and error is our only option.
- Each node requires both a fixed base fee and a proportional fee that depends on the transferred amount. When splitting, the sum of proportional fees remains unchanged, but the base fees multiply by the number of parts. This, combined with the fee budget (0.5% by default), means that below a certain part size we cannot split further without exceeding the fee budget.
- There is a maximum number of HTLCs that can be added to a channel before some must be settled. This is particularly worrisome since partial payments are only settled once all parts have reached the destination. If we’ve exhausted the available HTLCs on the routes to the destination, we must abort the overall payment given that there is no way for us to send the remaining parts.
- Having more parts in flight might give us a better view of the current state of the network—essentially probing the network for capacities and reachability—but at the same time it increases our chances of hitting a malfunctioning node resulting in a payment getting stuck.
Finally, there are a number of optimizations that we chose to implement since they presented no downsides. For example, we will consider a payment to have succeeded as soon as any part returned success. This considerably reduces the time until we can report success to whatever initiated the payment because the recipient would only ever accept any one part of the overall payment succeeded.
On the other hand, we can do the same if the payment cannot possibly succeed, for example, if the final node reports that the invoice expired, or that the only peer to the destination cannot forward the payment. In particular, this skips the MPP receiver timeout used to return parts of an incomplete payment.
So now that we know what to watch out for, we can look into how to split and when to split.
When to split? How to split?
We decided to split a payment into two distinct phases:
- The presplit: an upfront split into roughly equal-sized parts.
- The adaptive split: an interactive split based on what we learn from previous attempts.
Split Early
The upfront splitting happens before we even compute any routes to the destination. It takes the payment amount and splits it into smaller parts randomizing the amounts around a target amount.
The goal is to skip all attempts that are unlikely to succeed due to their size and homogenizes the parts to avoid telling the nodes along the route the overall payment amount. By ensuring we don’t try to send parts that are unlikely to succeed we can reduce the time to completion significantly.
In order to determine what the ideal size for the presplit would be, we probed the network (like we did a number of times before), this time not looking into reachability, but rather detecting the approximate capacity of channels along the path to a destination.
Probing the capacity of a route can be done by sending a probe with varying amounts to the destination, the largest successful amount is likely to be close to the current capacity. This scenario lends itself very well to the bisection method, using the amount as the variable and the success and failure as the function. The imprecision for individual measured capacities should not be too much of an issue, since we are interested in an estimate of what an average channel might look like.
The following histogram shows the results gathered probing 1559 random nodes in the network. Notice that this histogram shows single-part payments and gauges individual route capacities, not multi-part payments that are split over multiple routes.
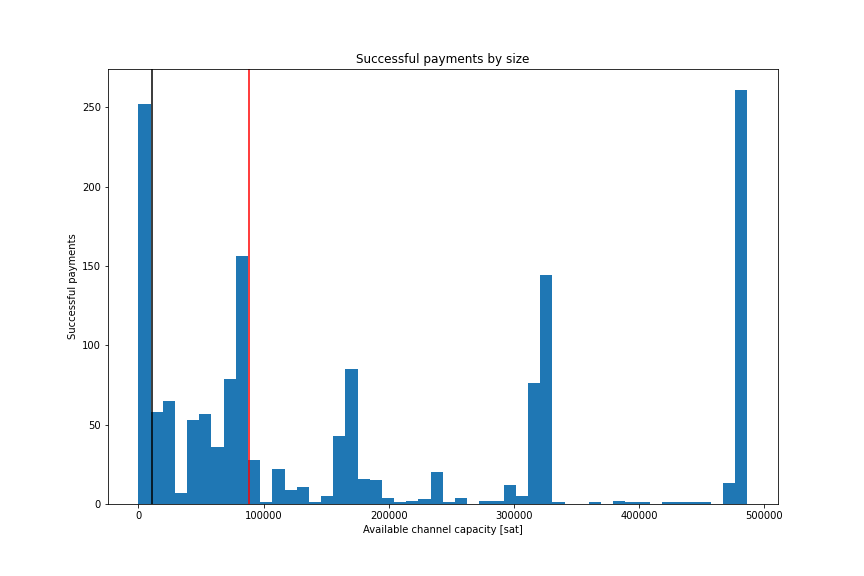
From the results, we can see that half the destinations have a route with a maximum capacity for a single part of 88,500 satoshis, while 83% have routes with over 10,500 satoshis. This means that if we split the payment into equal parts of 10,000 satoshis we’d expect over 80% to succeed without needing to be split further. We decided to use a presplit target value of 10,000 satoshis, randomizing in the range [9'000; 11'000] to obfuscate any residual that is not divisible by the target value.
This also gets us better privacy since all partial payments using these target values will look similar to routing nodes. Once we switch to point timelock contracts (PTLC), routing nodes will no longer be able to collate individual parts, thus helping to better obfuscate multiple payments by hiding in the traffic.
It is worth noting that these parameters will change over time as the network evolves. We will re-evaluate them on a regular basis and optimize them as appropriate.
Split Often
The adaptive splitting mechanism is performed interactively while sending the payment. If a partial payment fails to reach the destination, we learn a bit more about the channel constraints, such as capacity or whether we have exceeded the maximum number of HTLCs on the failing channel. We note this information in an overlay that is added on top of the information we exchanged with our peers through the gossip protocol.
Based on the combined information we can then decide whether retrying with the same amount and destination could possibly succeed. If it can be retried we will retry up to ten times before we split the partial payment into two halves. If there is no route the could be retried, we will split immediately. Since we now have changed the parameters of the payment, namely the amount, we potentially have new routes to try.
When splitting, we will split into two halves but also randomize as we did with the presplit mechanism in order to prevent a routing node from reversing the split to compute the amount of the previous attempts. But when do we stop splitting? We could just split in two until we have single millisatoshi parts, but is that a sensible choice?
It turns out that we can use two constraints to abort much earlier: the number of concurrent parts we can have in-flight is limited by the number of HTLCs that can be added to channels, and the overall fee, summed up over all parts, is going to exceed the fee budget. By default, c-lightning allocates a 0.5% limit on the fees that a payment may not exceed. As we split the payment into parts, we distribute this budget proportionally to the parts. Forwarding nodes leverage both a proportional fee and a fixed base fee. While the sum of proportional fees for parts remains constant, the base fee is multiplied by the number of parts, meaning that eventually, the base fee dominates the overall fee, and we exceed the fee budget.
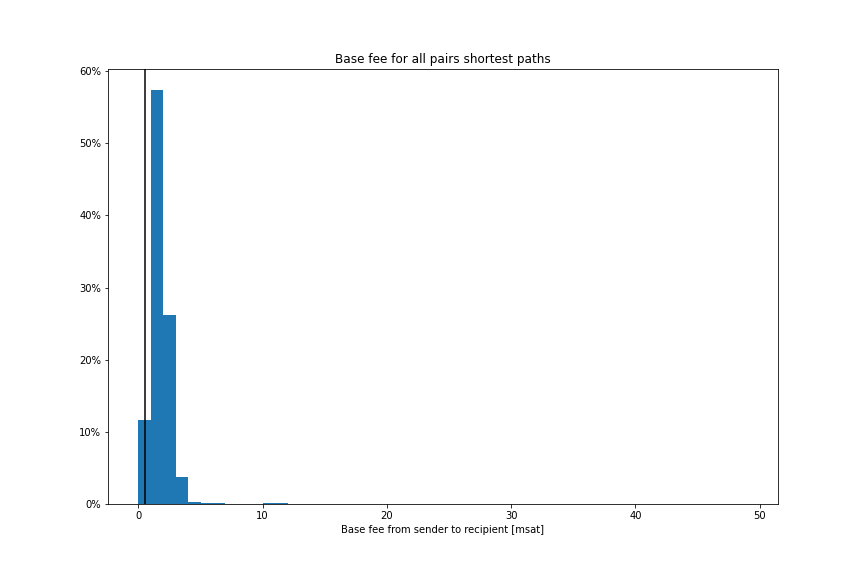
In order to limit the time to completion we measured the base fees on all sender-destination pairs in the currently active Lightning Network and came up with the following distribution:
From these measurements, we can infer that for partial payments below 100 sats in size, the base fee alone is sufficient to exceed the 0.5% fee budget allocated to that part, and we’d just be running in circles trying to find an acceptable route. The adaptive splitter will therefore not split further if the amount of a part is already below 100 sats in size. This was done in order to keep the time to completion low and to allow the user to retry manually, which might result in a different outcome.
Implementation
Before implementing the MPP splitting in the pay plugin, we decided to restructure our code in a way that is better suited to reuse the common payment flow across different use-cases. The basic payment flow consists of selecting a destination, computing a route to the destination, preparing the payloads and compiling them into a routing onion, sending that onion on its way, and waiting for the (partial-)payment to either succeed or fail. We decided to create a base payment flow with these steps, and adding extension points after each step where modifiers would be called that can modify the flow to implement specific aspects of a payment.
The basic payment flow, as well as some of the most common modifiers, are now part of libplugin which can be used by other plugins to implement custom payments. Moving all of the custom functionality into modifiers results in very clean, compartmentalized, code that is easy to reason about. Besides implementing the two MPP modifiers (presplitter and adaptive splitter) this modularization also made it easy to implement keysend as well as the aforementioned capacity probing plugin.
Upcoming Improvements
There are still a number of future improvements that we plan to implement over the coming releases. For one, we will be monitoring closely how the parameters affect the performance of multi-part payments and re-evaluate our analysis as the network evolves. So expect performance to improve over time.
We also have some more experimental improvements that we want to test. For example are considering implementing a mechanism, which we call fee-sharing, that would allow parts that exceed their own fee budget to borrow from the fee budget of already completed parts. This could allow for the few missing final parts to succeed, further increasing the probability of a successful overall payment. However, fee-sharing is complicated by the fact that we cannot know whether a part was successful or not, requiring further research before we can implement it.
As always we’re very interested in your feedback. If you have an idea on how we could improve the MPP implementation, criticism of what we did wrong, or want to share your experience, please feel free to reach out to us on IRC (#c-lightning on Freenode) or on Github.
Note: This blog was originally posted at https://medium.com/blockstream/all-paths-lead-to-your-destination-bc8f1a76c53d